
TL; DR
Three scenarios enable GitHub repositories to be hijacked. Linking directly to them may result in malicious code injection; don’t do it.
Background
A finding during a recent client engagement caused us to investigate the prevalence of dependency repository hijacking which is an obscure vulnerability that allows anyone to hijack a repository if its owner changes their username. This vulnerability is similar to subdomain takeover, trivial to exploit, and results in remote code injection. After analyzing open-source projects for this issue and recursively searching through their dependency graphs, we found over 70,000 impacted open-source projects; this includes popular projects and frameworks from companies like Google, GitHub, Facebook, and many others. To mitigate this issue, ensure that your project doesn’t depend on a direct GitHub URL, or use a dependency lock file and version pinning.
If you are familiar with Repo Jacking, jump straight to our Analysis.
What is Repo Jacking?
Dependency repository hijacking (aka repo jacking) is an obscure supply chain vulnerability, conceptually similar to subdomain takeover, that impacts over 70,000 open-source projects and affects everything from web frameworks to cryptocurrencies. This vulnerability is trivial to exploit, results in remote code injection, and affects major projects from companies like Google, GitHub, Facebook, Kubernetes, NodeJS, Amazon, and many others. After first discovering it in a recent engagement, we wanted to know how prevalent this vulnerability was, so we recursively analyzed all open-source projects and found that it is extremely widespread and most likely impacts you in some way.
Who is vulnerable?
Every project whose compilation depends on dynamically linked code from GitHub repositories is potentially vulnerable. For a project to be vulnerable, the following two things need to happen:
- Your code needs to directly reference a GitHub repository (usually as a dependency).
- The owner of that repository needs to then change/delete their username.
When the linked repository owner changes their username, it becomes immediately available to be re-registered by anyone. This means that any project that linked back to the original repository URL has now become vulnerable to remote code injection through dependency hijacking. A malicious attacker can register the old GitHub username, recreate the repository, and use it to serve malicious code to any project that depends on it.
Should you be concerned?
Even if your project that has a dependency on a GitHub repository isn’t vulnerable right now, if the owner of one of its dependencies changes their username, that project and all other projects that depend on the old link become vulnerable to repo jacking. You would expect there to be some kind of warning when repository changes locations, maybe a “404 - Repository not found” kind of error, but there is not. Additionally, there is one little Github feature that makes this vulnerability distinctly more dangerous: Repository Redirects.
‘Repository Redirects’ exacerbate the problem
When a GitHub user changes either the name of a repository or their username GitHub sets up a redirect from the old URL to the new one; this redirect works for both HTTP and Git requests. This redirect is created any time a user changes their username, transfers a repository, or renames a repository. The problem here is that if the original repository (in this case, “twitter/bootstrap”) is ever recreated, the redirect will break and send you to the newly created repository.
Example scenario:
- The link https://github.com/twitter/bootstrap points to the repository “twitter/bootstrap” but will actually redirect you to the “twbs/bootstrap” repository.
- If ever Twitter changed their GitHub username, anyone could then re-register it, recreate a repository named “bootstrap” and any new request to https://github.com/twitter/bootstrap would go to the newly created repository.
- Any project that depended on https://github.com/twitter/bootstrap would now start loading code from this new repository.
Redirection is a convenient feature since it means your links don’t immediately break when you rename your account. But it also means that your project can unknowingly become vulnerable to repo jacking. From your point of view, nothing has changed - your code still compiles the same, and everything works as it should. However, your project is now vulnerable to remote code injection, and you are none the wiser.
The 3 Hijack Scenarios
To get a little more specific, there are technically three different ways a repository can become hijackable:
- A GitHub user renames their account. This is the most common way a repository becomes hijackable since it is not uncommon for a user to rename their account and when they do, everything continues working as expected due to repository redirects.
- A Github user transfers their repository to another user or organization then deletes their account. When a user transfers a repository, a redirect is set up and by deleting their user opens it up to being hijacked by anyone.
- A user deletes their account. This is the least impactful of the three, since the moment the original user deletes their account, any project that references it will start having errors when trying to fetch the repo.
Note: There have been a few cases (one, two) of attackers re-registering the deleted username between the time the user deletes their account and projects try to fetch the repo. This scenario has been written about before here.
GitHub’s Response
We contacted GitHub before publishing this article, and they informed us that this is a known issue but that they currently do not have any plans to change the way redirection or username reuse works. They have provided some mitigations to this problem for some popular repositories by disallowing re-registering the names of repositories that have more than 100 new clones in the week leading up to their deletion, as outlined here. This does provide some degree of protection but is not a foolproof solution as many smaller repositories do not meet this criterion but can be still be depended upon by popular projects.
The root problem here is not so much that GitHub allows redirects and username reuse, but rather that developers are pulling their code from unsafe locations. GitHub cannot police developers who are using their service for unintended purposes. There are many package managers available (in fact, GitHub themselves has one) built to solve the problem of remote code dependencies, and developers have the responsibility of ensuring that they load their code from secure locations.
Analysis
Now the next question that comes to mind is, “How widespread is this really?”. It turns out that sifting through all open source projects, compiling their dependencies, finding all hijackable repositories, and constructing a dependency graph of vulnerable repositories is not easy. So, here is how we did it.

Step 1 – Data Collection
One of the hardest parts of performing large-scale analysis of open source software is the initial data collection. Finding an up to date, accurate, and easily searchable index of all the open-source projects is hard. We primarily used two datasets for this analysis:
- GitHub Activity Data
This is provided by Github themselves and is a huge dataset that includes over 2.8 million repositories, along with all of their files and contents; the entire dataset is over 3TB worth of content. Conveniently, it is hosted as a public BigQuery dataset on the Google Cloud Platform (GCP), which means that we can use BigQuery to run SQL commands over the entire dataset from within GCP itself, and we don’t have to download the entire 3TB+ file.
To actually perform the search, we generated a regex that catches any Github URL or other common Github dependency link formats such asgithub:username/reponame. Using this regex, we were able to extract the repository, file name, and file contents for each file that contains a reference to a GitHub link. This shrunk our search space down from 3TB+ to a more manageable 4GB. This filtered dataset included 4 million unique GitHub links and over 700 hundred thousand different Github users. - libraries.io
Librabries.io is an open-source project that aims to aggregate all the dependency from multi different packager managers into a graph-like dataset. This is amazing since not only does it do all the heavy lifting for us in linking what relies on what, but additionally they make the entire dataset available to download for free. Uncompressed, this dataset is over 100GB+ but can be loaded directly into a database for easier processing.
It was important that we use the two datasets because each one is good at different things. The “Github Activity Data” dataset allowed us to find every possible Github link referenced in a repository, even if it is not being used in an obvious place like a package manager manifest. Some of the most interesting findings were not necessarily direct code dependencies. We often found Github URLs used directly in a bash script to clone a repository or a docker image that would pull a repository from Github when built.

Example install script; the GitHub links are available to be registered by anyone.
Another common finding was hijackable repositories as Git submodules, something that would have been missed by standard dependency analysis.
The "libraries.io" dataset on the other hand was an already cleaned, filtered, and formatted dataset that allowed us to build a dependency graph and easily assess the extensiveness of this vulnerability. Together, these datasets gave us a more complete view of the overall impact of this vulnerability to open source projects.
Step 2 – Clean Up
Now that we had collected all this data, we needed to sanitize and normalize it. This was a sizeable effort since we needed to account for the different formats of each package manager. Additionally, we wanted to remove any links that were not actually being used as a dependency. Many of these links were used in comments, for example, something like: //code inspired from github.com/username/reponame, or in documentation text files. Since we were mainly concerned with the possibility of code injection, we trimmed off anything that was not going to be used directly by the code. This left us with a little over 2 million unique GitHub links that were referenced by files in meaningful ways.
Step 3 – Hijackable Usernames
Now that we have a clean(er) list of projects that directly depend on a GitHub link, we needed to find which users were currently unregistered. At this point, we had about 650k Github usernames that we had to sort through. Using the GitHub API we could check to see if a username exists, but we were rate limited to 5,000 requests an hour, which means that it would have taken us over 5 days to check all the usernames. With a little bit of clever logic and the GitHub GraphQL API, we were able to bring that down to a little over 2 hours to scan all 650k users.
So, what are the results? We found that about 7% (about 50k) of the usernames we collected are unregistered. We honestly were not expecting the number to be so high. We thought that less than 1% of the usernames we found were going to be hijackable. Apparently, people get bored with their usernames far more than expected.
Step 4 – Vulnerable Projects
Once we had all the hijackable usernames, it was just a question of doing a reverse search on our dataset for every project dependent on a repository owned by one of those usernames. After some further filtering and removal of false positives, we found a total of 18,000 projects directly vulnerable to repository hijacking. These projects have a combined GitHub start count of over 500,000 stars and include projects in virtually every language from some of the biggest open source organizations.
This number alone is terrifying, but modern codebases are not giant monolith living inside single repositories. Instead, they rely and depend on many other projects for functionality. This is great for maintainability and reusability, but it means that a vulnerability in a single popular dependency can greatly impact many projects down the dependency chain. Effectively any project that is dependent on one of the 18,000 directly vulnerable projects is itself also vulnerable.
Step 5 to ∞ – Dependency Analysis
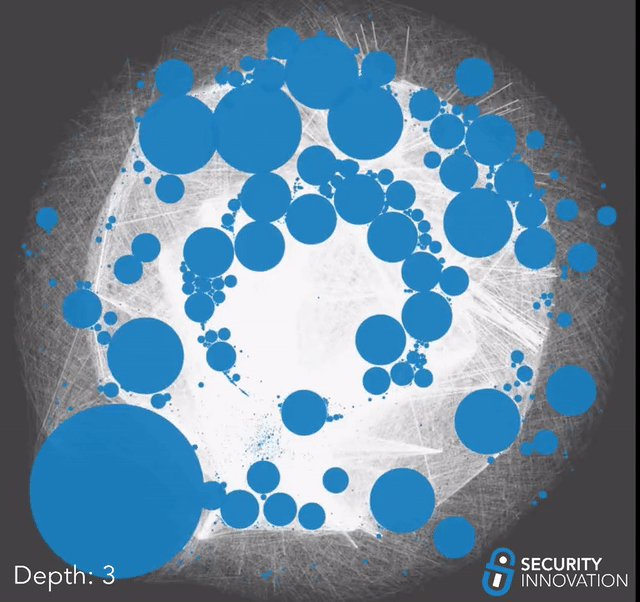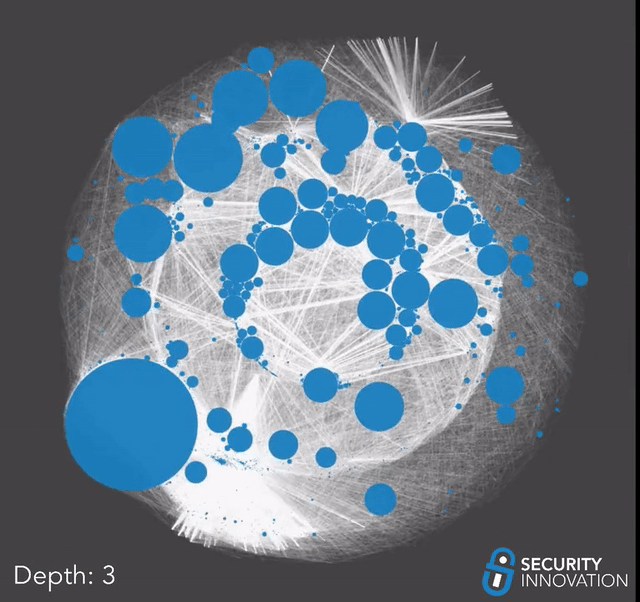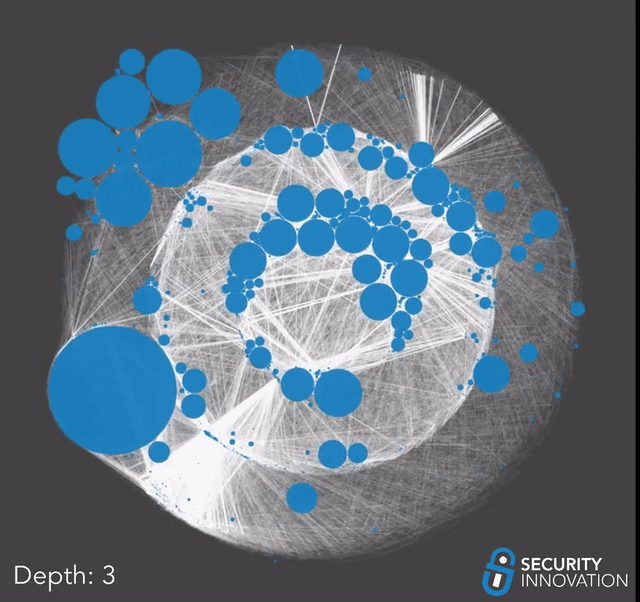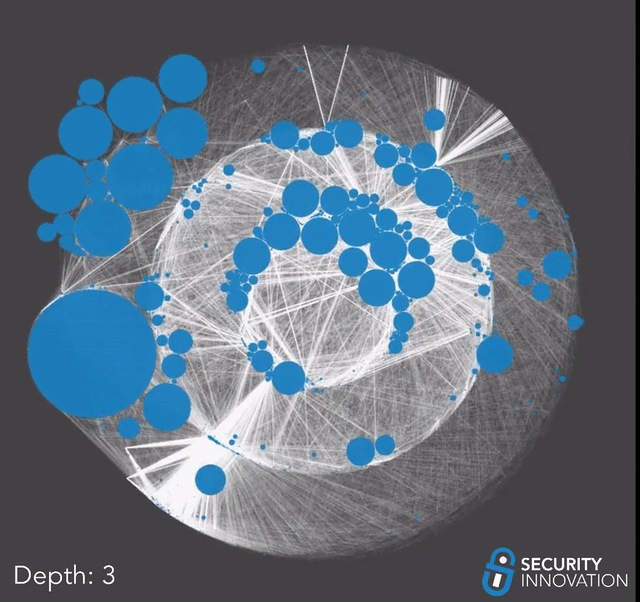
Now that we had a list of directly vulnerable projects, we used that along with our earlier dataset to perform a dependency graph taint search and find every project that depends on a vulnerable repo in their supply chain. For this analysis, we included normal dependencies and less obvious ones such as development dependencies or dependencies which are not in the main package manifest file. If one of these auxiliary dependencies is vulnerable to repo sniping, it might take a little longer for the impact to propagate up the dependency chain since it might only happen when the developers publish a new version. With that in mind, we began our taint analysis.
Due to the possibility that the list of vulnerable projects grows exponentially out of hand, we slowly walked the graph one depth layer at a time. Between each pass, we manually went through the results and trimmed off any obvious false positives to minimize error propagation and ensure our results did not get filled with false positives.
We had to stop after 5 passes.
Up until 5 passes, the data was growing predictably, and each round of search was taking a reasonable amount of time, but the moment we reached a depth of 6, the data started growing uncontrollably. Looking at the results for the 5th pass, the reason became clear; we had reached multiple huge frameworks that are foundational and depended on by thousands of other projects.
This was sufficiently deep for us to grasp the impact of this vulnerability. Overall, Security Innovation found over 70,000 impacted projects, with a grand total combined GitHub star count of over 1.5 million; that’s more stars than the combined total of the top 8 biggest GitHub repositories ever. It is hard to accurately measure, but we estimate that these projects have a combined total of at least 2 million daily downloads.
Impacted projects include repositories from huge organizations such as Google, GitHub, Facebook, Kubernetes, NodeJS, Amazon, and many others. Everything from small personal user projects to popular web frameworks used by hundreds of thousands of organizations is affected. It is also interesting to note just how many different types of software this affects. We found vulnerable router firmware, games, crypto wallets, mobile apps, and many other unique projects.
Mitigations
Now that we understand how impactful and widespread this vulnerability is, it is important to know what remediation options are available to protect your own project’s supply chain.
Don’t Link Directly to GitHub Repositories
This is the most obvious one: GitHub repositories are not, and have never claimed to be, a substitute for a package manager. There are no guarantees that GitHub links are static, and they should not be used as direct code dependencies. Using a dedicated package manager has many advantages, both from a usability and security perspective, and should always be preferred over directly linking to a repository. However, do note that you may still be vulnerable to repo jacking if one of your dependencies themselves directly links to a GitHub URL even if you check each of your transitive dependencies for direct links, one of those dependencies might still have a hidden dependency to a GitHub repo. We’ve seen this often with build scripts, which fetch code directly from a developer’s repository, or inside testing code. If it is vulnerable to a hidden repository hijacking, the next time that dependency gets updated, it could contain malicious code that then makes its way into your application.
Version Pinning and Lock Files
Another way to help mitigate this vulnerability is through version pinning and lock files. Version pinning is when a specific version is included with a dependency to ensure that only that version gets downloaded. In the context of GitHub link dependencies, this is often a SHA1 git commit hash, which is included to instruct your package manager tool to only download that specific commit of a git repository. The goal with this is that even if that repo gets hijacked, a malicious attacker would not be able to modify the code without also modifying the commit hash. You can also version pin a dependency to a specific branch or tag, but there is nothing to stop a malicious user from updating that tag or branch, so it does not provide any protection against repo jacking.
A lock file is a file made by your package manager tool that includes a list of version-pinned dependencies to ensure that next time someone tries to build that project, they download the exact same package and version specified in the lock file. Lock files can also sometimes include an integrity hash of the downloaded package to further ensure its authenticity.
Version pinning and lock file implementations are package manager specific, but most big packager managers support these features. That being said, they are far from foolproof. In fact, while we were conducting this research, we managed to bypass most major package manager’s version pinning and lock files. Stay tuned for a future blog post where we detail these issues in depth.
Vendoring
Vendoring is the act of downloading all your dependencies beforehand and including them in your repository. This has the advantage that your repositories are completely self-contained with the code needed to run them, and it also helps protect you against repo jacking. Since all your dependencies are already downloaded, it is like a lock file that also includes the content for your dependencies. Even if one of those dependencies gets hijacked, you have already downloaded the code you need. The caveat here is that you might still become vulnerable the next time you update your dependencies if one of those dependencies has been hijacked. Many developers just update all their dependencies when their package manager tells them to, without looking that the specific changes that were made. In these cases, vendoring provides very little protection as it only works if you keep a close eye on dependency upgrades.
Conclusion
Hopefully, this article helped shed some light on the impacts of dependency repository hijacking and allow projects to better secure their dependencies supply chains. The proliferation of COTS, 3rd party software, and open source will continue to expand, and along with it, so will the number of attacks targeting them. Although the use of 3rd party dependencies get features out the door quicker and reduces development time, it is critical that you scrutinize them the same way you do your own code - perhaps even more so.